Künstliche Intelligenz (KI) entwickelt sich zum Allround-Werkzeug im Gesundheitswesen: Ihre Einsatzbereiche reichen von der Biomarker- und Pharmaforschung über die Diagnostik, etwa in Pathologie und Radiologie, bis hin zur klinischen Entscheidungsunterstützung, beispielsweise bei personalisierten Krebstherapien.
Und in Zukunft werden die Einsatzmöglichkeiten von KI noch zahlreicher, weil immer mehr Daten zur Verfügung stehen. Anamnesen und Befunde, die früher auf Papier „gespeichert“ waren, werden zunehmend digitalisiert und damit maschinenlesbar, und auch Patient*innen selbst sammeln mit Wearables und Apps immer mehr auswertbare Daten über ihre eigenen Körper.
Vielseitige Black Box
Eine häufig gehörte Kritik am Einsatz von künstlicher Intelligenz, im Gesundheitswesen und anderswo, ist jedoch: Die Algorithmen seien eine „Black Box“ – die Anwenderin könne nur sehen, was in das Programm hineingeht und was schließlich ausgespuckt wird. Der Weg vom Input zum Output — von den Patientendaten zu Wahrscheinlichkeiten, Diagnosen, Empfehlungen — sei aber völlig unklar.
Dies unterscheidet den „Kollegen Computer“ von allen anderen Kolleginnen und Kollegen: Von einem menschlichen Experten kann man sich erklären lassen, warum er eine Veränderung im histopathologischen Schnittbild für gutartig hält oder weshalb er ein bestimmtes Regime der Chemotherapie einem anderen vorzieht. Machine-Learning-Algorithmen dagegen schweigen sich zu den Gründen für ihre Entscheidungen aus — noch.
Bias und Fehldiagnosen
Dies stellt Entwickler*innen und Ärzt*innen vor eine ganze Reihe von Problemen: Wie lassen sich Fehler im Entscheidungsprozess aufspüren? Wie kann man unfaire und gefährliche Bias (Voreingenommenheit) in einem Algorithmus feststellen? Solche entstehen etwa durch eine unausgewogene Zusammensetzung der Trainingsdaten: So sind diagnostische Algorithmen in der Dermatologie schlecht darin, Hautkrebs bei dunkelhäutigen Patient*innen zu diagnostizieren, wenn sie — wie es meistens der Fall ist — mit Bildern von mehrheitlich hellhäutigen Patient*innen trainiert worden sind.

Ein noch frappierenderes Beispiel ging vor einigen Jahren durch die Presse: Die Google-Bilderkennung war ebenfalls hauptsächlich mit Bildern hellhäutiger Personen trainiert worden, was dazu führte, dass der Google-Algorithmus Afroamerikaner auf Gruppenfotos als „Gorillas“ taggte.
Hierbei handelt es sich um Probleme, die aufgrund fehlender Daten (beispielsweise von dunkelhäutigen Personen) entstehen. Doch ebenso problematisch sind Schlussfolgerungen, die in korrekter Weise aus ebenfalls korrekten Daten gezogen werden, aber zu Diskriminierung einzelner Personen(gruppen) führen. Möglicherweise haben etwa Leute, die in den sozialen Netzwerken viele Kontakte aus Stadtteilen mit niedrigem Durchschnittseinkommen haben, tatsächlich ein höheres Risiko, einen Kredit nicht zurückzahlen zu können. Wenn Banken ihnen daraufhin höhere Kreditzinsen berechnen, führt das trotzdem zu einer strukturellen Benachteiligung von Menschen, die diese Situation nicht beeinflussen können. Ähnliche Konstellationen sind auch im Gesundheitswesen denkbar — wenn man sich beispielsweise vorstellt, dass ein Algorithmus die Wahrscheinlichkeit für einen Rückfall in die Alkoholabhängigkeit für einen Patienten berechnet und davon die Entscheidung für oder gegen Lebertransplantation abhängig ist.
(Kein) Vertrauen in den Algorithmus
Schon IBM Watson ist im klinischen Einsatz daran gescheitert, dass Ärzt*innen im Zweifelsfall ihren eigenen Entscheidungen vertrauten — und nur dann auch Vertrauen in Watson hatten, wenn dieser zufällig zur gleichen Diagnose gekommen war.
Ein weiteres Problem: Wie lässt sich der Einsatz von KI gegenüber Patient*innen rechtfertigen? Setzen diese ihr Vertrauen nicht in die Ärztin, die ihnen gegenübersitzt, statt in den Algorithmus? Wenn diese die Entscheidungen des Algorithmus nicht nachvollziehen kann, wie kann sie diese dann den Patient*innen vermitteln?

Die Auswirkungen von künstlicher Intelligenz, die immer häufiger als intransparente Black Box in verschiedenen Lebens- und Wirtschaftsbereichen eingesetzt wird, werden seit einigen Jahren im einem Forschungsgebiet namens Responsible AI („Verantwortungsbewusste KI“) untersucht.
Responsible AI und Explainable AI
Responsible AI beschäftigt sich mit den ethischen Fragestellungen beim Einsatz von künstlicher Intelligenz. Ein wichtiger Baustein der Responsible AI ist Explainable AI — künstliche Intelligenz, deren Wirkungsweise und Schlussfolgerungen für Menschen durchschau- und verstehbar sind. Explainable AI soll nachvollziehbare Erklärungen dafür liefern, wie aus einem bestimmten Datensatz eine bestimmte Schlussfolgerung (etwa eine Wahrscheinlichkeit oder eine Klassifikation) gezogen wurde.
Untersuchungen haben gezeigt, dass das Vertrauen von Versuchspersonen in einen Algorithmus, der ein unerwartetes Ergebnis geliefert hat, durch eine Erklärung dieses Ergebnisses gesteigert werden kann. Bei erwarteten Ergebnissen — wie etwa im obigen Beispiel von IBM Watson, wenn dieser zur gleichen Diagnose kam wie behandelnde Ärzt*innen — macht es für das Vertrauen der Versuchspersonen in den Algorithmus kaum einen Unterschied, ob eine Erklärung mitgeliefert wird.
DSGVO: Recht auf Erklärung und Transparenzgebot
Abgesehen von der Möglichkeit, Bias und Diskriminierung in Machine-Learning-Algorithmen zu erkennen und zu korrigieren, und von dem potenziellen Vertrauensgewinn bei Nutzern, hat Explainable AI noch einen Vorteil: Konflikte mit der DSGVO — zumindest in Bezug auf die Transparenz des Algorithmus — werden vermieden.
Ein ausdrückliches „Recht auf Erklärung“ für Betroffene ist in der europäischen Datenschutz-Grundverordnung (DSGVO) zwar nicht verankert. Allerdings enthält die DSGVO ein Transparenzgebot, das besagt:
Bei einer automatisiert getroffenen Klassifikation oder Entscheidung haben Betroffene das Recht, Auskunft über die „bedeutungsvollen Parameter“ dieser Entscheidung zu erhalten.
Explainable AI: ante-hoc und post-hoc
Wie funktioniert nun Explainable KI?
Zunächst: Algorithmen aus dem Machine Learning müssen nicht zwingend für den Menschen unverständlich sein. Es gibt Methoden, die in ihrer simpelsten Ausführung leicht durch den menschlichen Nutzer nachvollzogen werden können. Ein Beispiel hierfür ist der Entscheidungsbaum (Decision Tree).
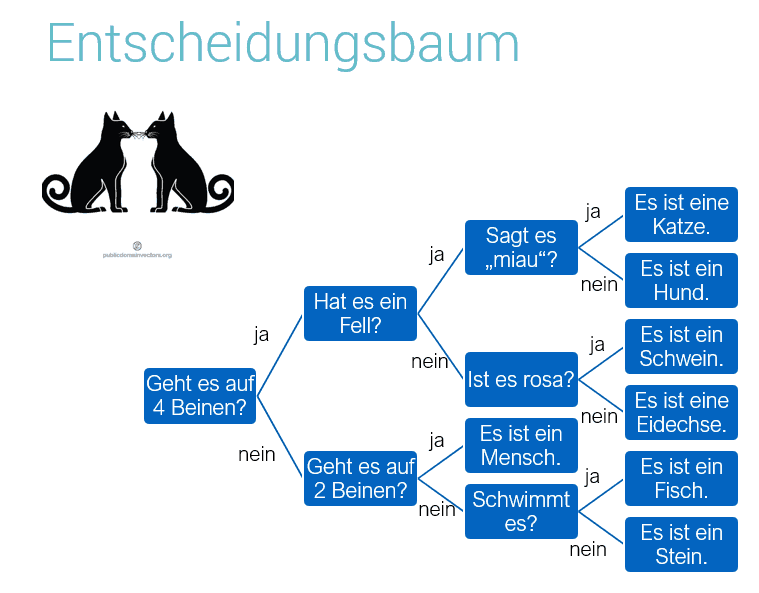
Dies ist schon ein einfacher Vertreter der ersten Art von Explainable AI, nämlich den sogenannten Ante-hoc-Verfahren (ante hoc = lat. „vor diesem“). Bei Algorithmen, die „ante hoc“ erklärbar sind, kann man gewissermaßen schon vor dem Ergebnis den Weg der Daten durch die Verarbeitung verfolgen und verstehen, warum der Algorithmus diese oder jene Abzweigung nimmt.
Hier kommt aber auch gleich schon die Einschränkung: Wenn der Sachverhalt so einfach ist, dass der Entscheidungsbaum übersichtlich bleibt, dann ist der Einsatz von Machine Learning an dieser Stelle überflüssig. Die Stärken von Machine Learning und KI sind ja gerade die Verarbeitung von und Schlussfolgerung aus einer größeren Menge von Daten, als die menschliche Intelligenz auf einmal managen kann.
Erklärbarkeit vs. Präzision
Zudem sind nicht alle Verfahren, die in Machine Learning und KI verwendet werden, ante hoc erklärbar — beispielsweise die mittlerweile weit verbreiteten neuralen Netzwerke mit ihren verschiedenen Unterformen nicht.
Der Algorithmus mit der besten Trefferwahrscheinlichkeit in einem bestimmten Anwendungsgebiet muss nicht gleichzeitig erklärbar sein. Oder: Der Algorithmus mit der höchsten Genauigkeit ist nicht gleichzeitig der mit der besten Erklärbarkeit.
Konkret: Wenn man die Wahl zwischen dem Algorithmus hat, der in der Mammographie mit der besten Genauigkeit Brustkrebs erkennt, und dem, der für die Radiologin am besten nachvollziehbar (erklärbar) ist, für welchen sollte man sich entscheiden? Dieses Dilemma wird in der englischsprachigen Literatur auch als „Accuracy – Interpretability Trade-Off“ bezeichnet.
Aber auch hierfür wird bereits an Lösungen gearbeitet: Das Stichwort ist „post hoc“ Erklärbarkeit.
Post-hoc-Verfahren: Erklärung wird nachgeliefert
Post hoc (lat. „nach diesem“) bedeutet in diesem Zusammenhang, dass der Machine-Learning-Algorithmus seine Entscheidung trifft und die Erklärung für diese im Nachhinein geliefert wird. Wie genau dies geschieht, hängt von der jeweiligen Implementation ab.
Ein Post-hoc-System ist beispielsweise Local Interpretable Model-Agnostic Explanations (LIME) von Marco Ribeiro und Mitarbeitern.
LIME funktioniert zur Zeit mit allen Machine-Learning-Algorithmen in der Programmiersprache Python, die die Eingabedaten in zwei oder mehr Klassen einteilen und für jede Klasse eine Wahrscheinlichkeit zurückliefern.
Die Erklärungen in LIME beziehen sich immer auf eine konkrete Entscheidung des Algorithmus. Angenommen beispielsweise, man arbeitet mit einer Bilderkennung, die Bilder von Vierbeinern in Katzen und Hunde klassifizieren soll und ein bestimmtes Bild als Katze erkannt hat. Hier kann man sich nun von LIME innerhalb des Bildes die Region markieren lassen, die für die Entscheidung „Hund“ bzw. „Katze“ ausschlaggebend war — etwa die Form der Augen-Schnauze-Region.

Ähnlich funktioniert es bei der Klassifikation von numerischen Datensätzen: In diesem Beispiel des Wisconsin Breast Cancer Data Set wird für jede richtige (und falsche) Klassifikation in gutartig/bösartig angegeben, welche Parameter (Zellgröße, Mitosen etc.) für die Entscheidung ausschlaggebend waren.
Wie schafft LIME es, die Entscheidungen so unterschiedlicher Algorithmen im Nachhinein zu erklären? Es nimmt den Input, der zu einer bestimmten Entscheidung geführt hat, und permutiert diesen, erzeugt also viele Datensätze, die dem originalen Datensatz ähnlich sind. Diese werden dann ebenfalls als Input in den Algorithmus gegeben und es wird beobachtet, wie sich die Entscheidungen des Algorithmus ändern. Wenn also etwa in einer Permutation des Datensatzes das Feature „Zellgröße“ leicht verändert ist und dieses aber zu einer deutlich anderen Klassifikation führt, dann ist offensichtlich die Zellgröße sehr wichtig für die Entscheidung des Algorithmus.
Hier wird schon deutlich, dass LIME keine Aussage darüber trifft, wie der Algorithmus tatsächlich in seinem Inneren funktioniert — LIME beobachtet nur den Zusammenhang verschiedener Inputs mit verschiedenen Outputs, und leitet aus diesen ein lineares Modell ab. Dieses ist nur lokal gültig — bei einer anderen Instanz aus dem Datensatz ist im obigen Beispiel die Zellgröße bei der Klassifikation vielleicht völlig irrelevant gewesen.
LIME erklärt also genau genommen keinen Algorithmus, sondern nur dessen einzelne Entscheidungen.
Dennoch handelt es sich um ein nützliches Verfahren — vor allem, wenn man es auf Entscheidungen des Algorithmus anwendet, die für menschliche Beobachter überraschend erscheinen. So kann man Bias oder Overfitting im Algorithmus entdecken und im Sinne eines Feature Engineering korrigieren.
Explainable AI ist — aus all den oben besprochenen Gründen — ein spannendes Tool vor allem für automatisierte Diagnostik und Entscheidungsunterstützung (Clinical Decision Support) im Gesundheitswesen. So hat Biomed Central aktuell einen Call for Papers zum Thema Explainable AI ausgerufen, dessen Ergebnisse Ende August 2019 in Canterbury (UK) präsentiert werden.
Mehr zum Thema KI im Gesundheitswesen lesen Sie hier im Editorial von Manfred Kindler in der aktuellen mt medizintechnik – und weitere Updates zum Thema „Explainable AI im Gesundheitswesen“ demnächst hier im Blog!



2 Trackbacks / Pingbacks
Comments are closed.